【python】pandasにてヘッダー(header)を飛ばす方法【複数行のヘッダーがある場合など】
大量の科学的データを解析する際には、pythonを初めとしたデータ加工に長けたプログラミングを理解しておくと便利です。
例えば、python(jupyternotebook使用)のpandas機能にてデータをデータフレーム(dateframe)で扱う場面がよくありますが、ヘッダーが複数行ある場合に飛ばして読み込む方法について理解していますか。
ここでは、pandasにてヘッダーを飛ばす(複数行ある)場合の対処方法について確認していきます。
・pandasにてヘッダーを飛ばす方法【csvなどで複数行のヘッダーがある場合】
・skiprowsでもヘッダーを飛ばして表示させられる
というテーマで解説していきます。
pandasにてヘッダーを飛ばす方法【csvなどで複数行のヘッダーがある場合】
pandasにて複数行のヘッダーがあるcsvやexcelを読み込む場合、デフォルトの読み込み方で対応しますと以下のようデータの中にヘッダーが含まれてしまいます。
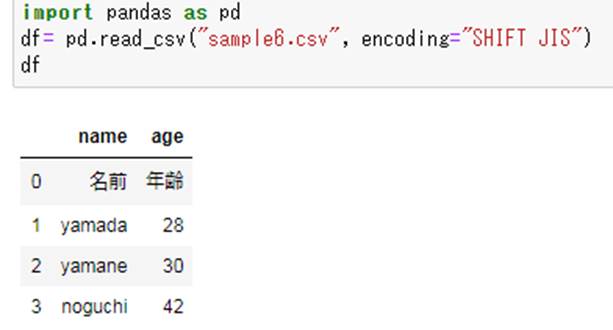
このように複数行ヘッダーがある場合では、最も上のヘッダー行を飛ばすとよく、具体的にはread_csv関数内の引数に
と指定すればいいです。
併せたサンプルコードは以下の通りとなります。なお、ディレクトリ内に以下のcsvやexcelファイルが存在しない場合はまずカレントディレクトリの移動を行いましょう。
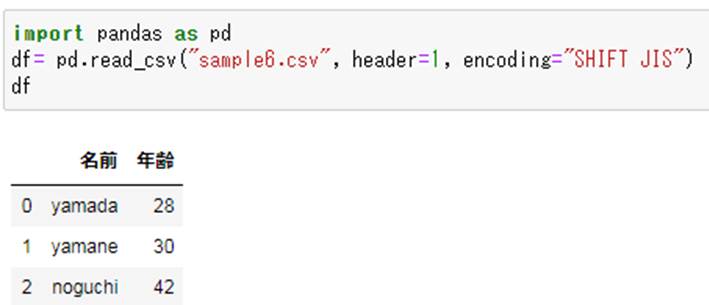
df= pd.read_csv("sample6.csv", header=1, encoding="SHIFT JIS")
df
すると以下のよう、ヘッダーを飛ばしてcsvを読むこむことに成功しました。
なお、csvでなくexcelであっても、read_excelの関数を活用するだけで後は同じです。
この時header=x のxの数値を変えれば、読み込むcsvやexcelのヘッダー行を指定できるので、適宜調整していきましょう。
skiprowsでもヘッダーを飛ばして表示させられる
上では引数にheader=1と入れることでヘッダーを飛ばして読み込めましたが、代わりにskiprows=1と入れても同じ結果となります。
ソースコードは以下の通り。
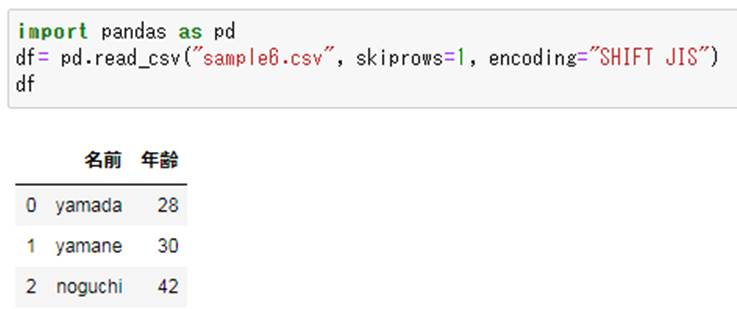
import pandas as pd
df= pd.read_csv("sample6.csv", skiprows=1, encoding="SHIFT JIS")
df
こちらのコードでも複数のヘッダーがある1行目を飛ばして、2行目のみから読み込むことが可能となります。
関連記事
Pandasでcsvの読み込みを行う方法【Python】
Pandasでヘッダーの変更(データフレーム)を行う方法【csvやexcelの読み込み時:Python】
【python】pandasにてヘッダー(header)を飛ばす方法【複数行のヘッダーがある場合など】 関連ページ
- 【matplotlib】x軸(軸ラベル)を回転させる方法【python(pandas)】
- 【pandas】csv読み込み時にディレクトリ(フォルダ)を指定する方法【python(pandas)】
- 【python】csvの書き込み(保存)時に列指定を行う方法【pandas(jupyternotebook)での出力】
- 【python】csvの保存先を指定する方法【pandasにおけるdataframe(jupyternotebook)】
- 【python】pandasにて最大値の2番目や最大値を計算する方法【2番目に大きい】
- 【python】pandasにて欠損値(NAN)を補完(置換)・削除する方法【空白行の削除】
- 【python】pandasにてヘッダーの変更(データフレーム)を行う方法【csvやexcel読み込み時など】