【python】csvの書き込み(保存)時に列指定を行う方法【pandas(jupyternotebook)での出力】
大量の科学的データを解析する際には、pythonを初めとしたデータ加工に長けたプログラミングを理解しておくと便利です。
例えば、python(jupyternotebook使用)のpandas機能にてcsvを読みこんだり、直接書き込むことによってdaraframe(データフレーム)を作成することがよくあります。
この時、データフレームをcsvデータとして出力(to_csv)することがありますが、このcsvの中の特例の列のみを指定して出力(保存)する方法について理解していますか。
ここではpythonのpandasにて列指定をしてcsv保存(書き込み)を行う方法について解説していきます。
・pandasにて列指定をしてcsv保存(書き込み)を行う方法【pythonにおける特定列のcsv出力】
というテーマで解説していきます。
pandasにて列指定をしてcsv保存(書き込み)を行う方法【pythonにおける特定列のcsv出力(columnsを使用)】
それでは、実際のデータ(架空のもの)を使用して、pythonのpandasにてcsvw保存する際に列指定を行う方法について確認していきます。
まずは、以下のような元のcsvデータをpandasにて読みこむとします。
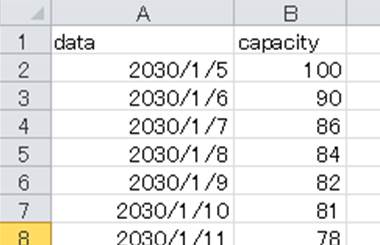
このcsvデータにおいて、capacityの列のみを指定して、それをcsvデータとして書き込みたいケースがあるでしょう。
このようなpandasでのcsvデータの列指定を行って保存するには、以下のto_csv(csv書き込み)を行う際に、columnsのコードを入れるといいです。
具体的には以下のようなコードとなります。
import pandas as pd
df = pd.read_csv("C:/sample/sample1.csv", encoding="SHIFT_JIS")
df.to_csv("shuturyoku1.csv", columns=["capacity"], index=None)
これだけで特定の列のみに変更したcsvの保存を行うことができました。
なお、今回はindex=None(もしくはindex=Falase)のコードを入れているため、列指定して書きこみしたcsvのインデックスは無い状態です。
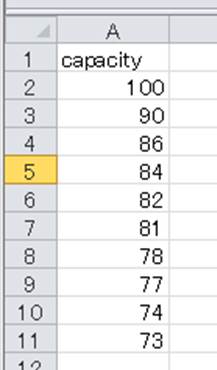
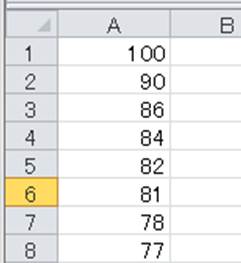
ヘッダーも消したいのであれば、header=None(もしくはheader=Falase)を入れていくといいです。
複数列を指定したcsvの出力(保存)もpandasでできる【python】
上では、capacityの一列のみを指定して、csvの出力を行いましたが、これだけでなく複数列でも対応できます。
import pandas as pd
df = pd.read_csv("C:/sample/sample1.csv", encoding="SHIFT_JIS")
df.to_csv("shuturyoku5.csv", columns=["capacity" , "data"] , index=None)
以下が特定の複数列のみが書き込み(保存)されたcsvのデータです。
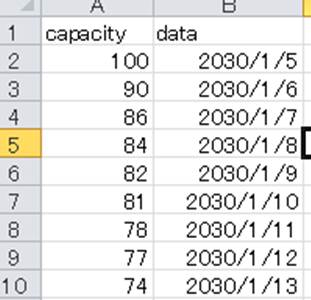
pythonのpandasが使えるとcsvやexcelデータを開かずに処理できるので、大量のデータを扱う際には、かなり対応速度が上げられます。
【python】csvの書き込み(保存)時に列指定を行う方法【pandas(jupyternotebook)での出力】 関連ページ
- 【matplotlib】x軸(軸ラベル)を回転させる方法【python(pandas)】
- 【pandas】csv読み込み時にディレクトリ(フォルダ)を指定する方法【python(pandas)】
- 【python】csvの保存先を指定する方法【pandasにおけるdataframe(jupyternotebook)】
- 【python】pandasにて最大値の2番目や最大値を計算する方法【2番目に大きい】
- 【python】pandasにて欠損値(NAN)を補完(置換)・削除する方法【空白行の削除】
- 【python】pandasにてヘッダーの変更(データフレーム)を行う方法【csvやexcel読み込み時など】
- 【python】pandasにてヘッダー(header)を飛ばす方法【複数行のヘッダーがある場合など】